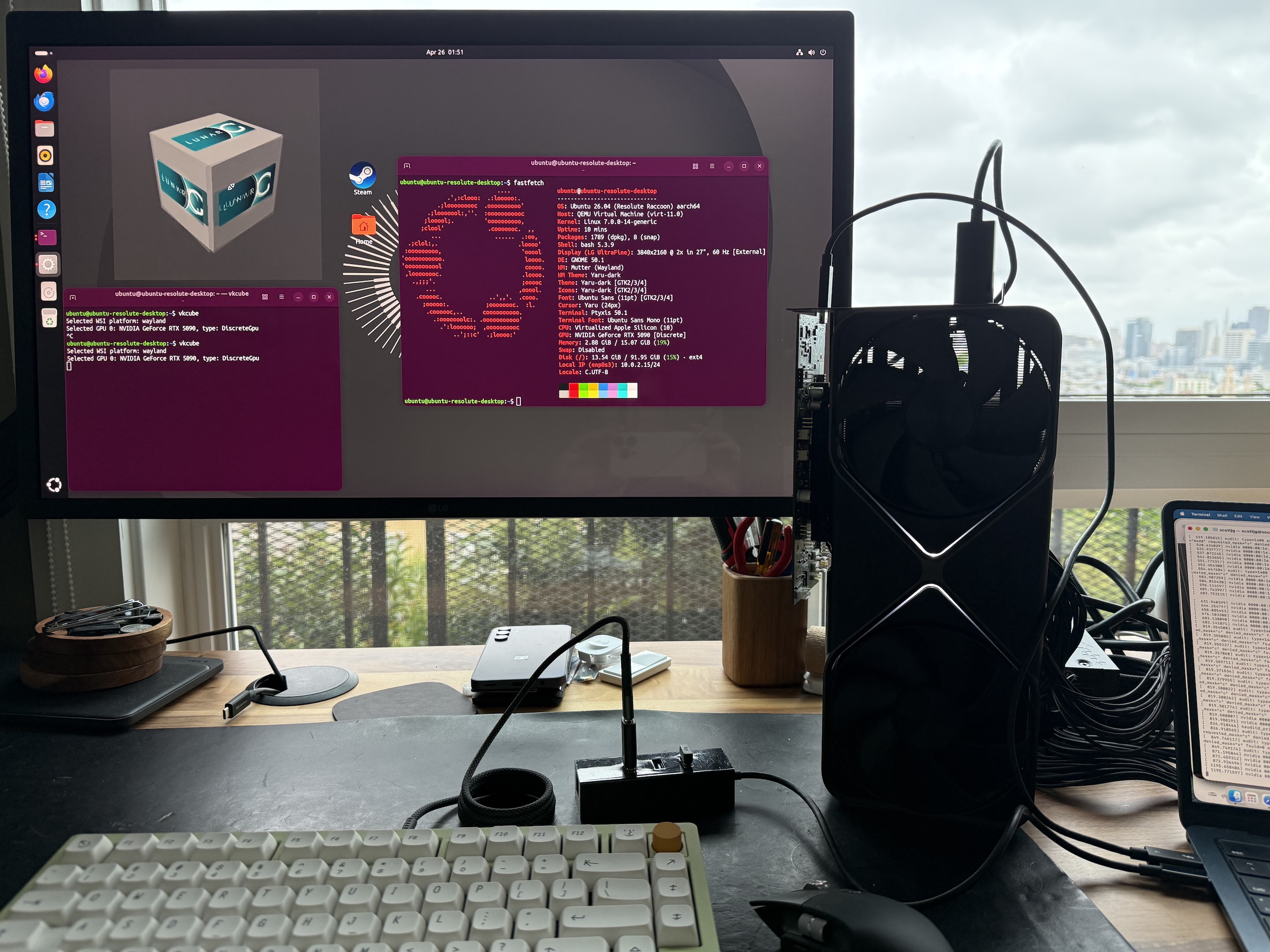
This is an extraordinary technical deep-dive into connecting an NVIDIA RTX 5090 to an M4 MacBook Air via Thunderbolt eGPU, running games and AI workloads through a Linux VM with PCI passthrough.
Engineering Achievement
The author engineered a complete solution for GPU passthrough on Apple Silicon, including:
- Custom virtual PCI device (
apple-dma-pci) to work around DART’s 1.5GB mapping limit - Kernel driver patches using kprobes to fix NVIDIA driver alignment issues
- DMA clustering algorithm to stay under the 64k mapping count limit
- Hardware TSO mode implementation for x86 memory ordering emulation
Performance Results
Gaming (Cyberpunk 2077 4K RT Ultra):
- M4 Air native: 3fps (unplayable)
- M4 Air + eGPU: 27fps or 111fps with DLSS framegen (playable)
- Gaming PC (native PCIe): 100fps or 282fps with framegen (2-4x faster)
AI Inference (Qwen 3.6):
- M4 Air native: 22 tok/s, 17s prefill (4K tokens)
- M4 Air + eGPU: 155 tok/s, 150ms prefill (120x faster prefill)
- Scales much better with concurrent requests
Technical Innovations
The article solves multiple hard problems:
- Working around macOS kernel panics when mapping device memory with
HV_MEMORY_EXEC - Implementing demand-paging style DMA mapping to work within DART constraints
- Using memory clustering to reduce mapping counts by 4x
- Hot-patching NVIDIA driver behavior via kprobes to avoid forking
Practical Limitations
Despite the impressive engineering, this is firmly a “look what’s possible” project rather than production-ready:
- Requires unreleased Apple entitlements
- x86 emulation overhead cuts effective CPU performance in half
- Some games exceed DART limits and won’t start
- Steam stability issues
- Native gaming PC is still 2-4x faster
Best Use Case: AI Inference
The most practical application is local AI inference, where:
- CUDA runs natively on ARM64 Linux (no emulation penalty)
- Prefill performance improves by 100x
- Concurrent request handling scales much better than on integrated GPUs
- Beats the M4 Max Mac Studio for batched inference
This is one of the most technically impressive hardware hacking projects I’ve seen, with exceptional documentation of both the problems encountered and solutions developed.